Windows USB Storage Parser (usp)
Introduction
usp is a command line tool that can be scripted to work with other tools. It automates various manual techniques for extracting and analyzing different registry entries and Windows log files, to pull together a report that documents the USB activity on a Windows computer. The report displays a summary of the USB device, timestamps of when the device was initially plugged, last time the device was plugged in, and various other metadata.
There are 5 use-cases that the Windows version of usp handles. It can process USB artifacts from: (a) a live Windows system, ranging from Windows XP up to Windows 2011, (b) an image of a Windows hard drive, (c) extracted registry hives and setupapi logs, (c) an external drive that was mounted and (d) a monolithic VMWare virtual disk file.
usp has been built so it relies simply on the standard operating system libraries. This means it does not require any extra libraries (DLLs) to be installed on the system for it to run. For any critical parsing, usp uses its own internal algorithms. This means for registry reading and traversals, it doesn't make use of the Windows API calls. Therefore, if the system you are analyzing has been compromised, usp should be able to extract what it needs and process the data without losing additional integrity in the data. Since there is no installer for usp, it is easy to run directly from a USB stick or CD.
While usp gathers USB device statistics on Windows operating systems, it can be run on other operating systems in a limited mode. If one wishes to analyze Windows forensic artifacts off-line on Linux or Mac OS-X, there is a compiled version of usp to handle these operating systems as well.
usp has been made available for free 'personal' (non-commercial) use and can be downloaded at the end of this page. See the licensing agreement for more details prior to use.
Which Windows artifacts are used
There are currently three different sources of Windows artifacts that are needed for usp to successfully process USB device statistics. These include: (a) the setupAPI log(s), (b) the system and software hives, (c) the user registry hives, (d) the AmCache hive, and (e) certain event logs. The setupAPI log is one or more files that identifies, amongst other things, when a USB device was initially plugged in. The system hive identifies which USB devices were registered with the Windows plug and play manager. Windows sets up many registry keys so that it can identify that same device quickly next time it is plugged in. The user hives are used to associate which user account was logged on when the USB device was plugged in. This artifact can help identify when a user last plugged in the device. Finally, as Windows includes more event data for USB device, the certain logs are useful in recording USB device driver install, device inserts, and device removable. As more research in Windows USB forensics becomes available, it can be incorporated into usp to encompass more artifacts.
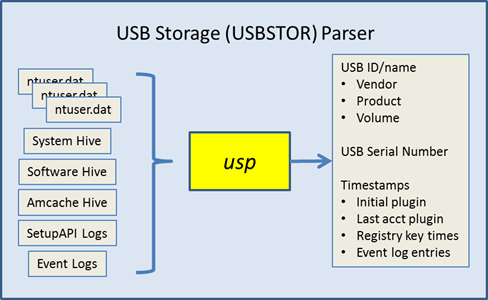
When mapping the output to these artifacts, it can be confusing. Therefore, the following graphic was generated to show which artifact correlate to which timestamp output field.

As one can see there are various sources for timestamp data, and yes, some of them are redundant. The first source, which is common across all versions of the Windows operating systems are the registry last modification times for their respective subkey path. One can also use the SetupAPI log(s) to extract installation time. In Windows 7, the device installation date property identifier should be present as well as the EMDmgmt timestamp(s) (EMDmgmt registry data is related to ReadyBoost data). In Windows 8, the device last arrival/removal dates property identifiers may also be present. While it may seem redundant to display multiple timestamps, the extra data allows the investigator to cooroborate that certain actions took place, and thus, increase the confidence the behavior suggested by the data was not influenced by anti-forensics techniques.
Aside from the timestamp data, usp displays other metadata about the USB device. Below is an example of this same device, with the timestamp data removed to focus on the other output.
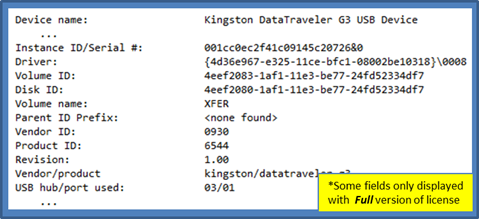
The instance ID (or serial number) is one of the main pieces of data that links many of the various artifacts together. The volume identifier links the data in the system hive to the USB data in the user hive to correlate which user account mounted the USB device. The parent prefix ID is more useful in pre-Vista versions of Windows to provide linkages between data. The vendor ID, product ID, revision, and product name are pulled directly from the registry information about the device. Finally, the USB hub/port combination is extracted which records where the device was plugged into.
Available options
There are 5 use-cases that usp was designed for. Not all the use-cases can be used with all usp's binaries. Below is a breakout listing which binaries are compatible with each use-case:
- - Live Windows processing (Win32/64 binaries)
- - Off-line processing of a 'dd' image of a disk or volume (Win32/64, Linux32/64 and Mac OS-X 32/64 binaries)
- - Off-line processing of extracted registry hives and setupAPI logs (Win32/64, Linux32/64 and Mac OS-X 32/64 binaries)
- - Processing an external mounted drive (Win32/64 binaries)
- - Processing a monolithic VMWare NTFS formatted virtual disk (Win32/64, Linux32/64 and Mac OS-X 32/64 binaries)
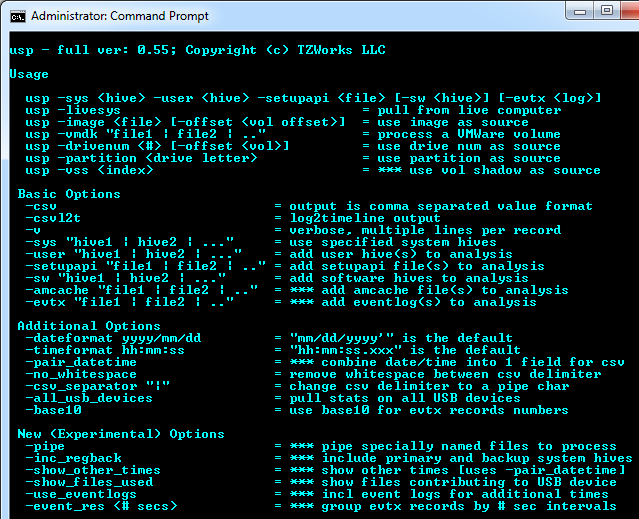
The options on the command prompt menu reflect these use-cases, but are grouped as follows: (a) Live system processing (b) off-line processing, and (c) experimental options. See the figures below for examples of the display menu for Windows and for Linux, respectively (note: Mac OS-X has the same menu as Linux).
Example 1. Processing USB Artifacts from a Live Windows System
While the most difficult to implement, this use-case is the easiest to use. To run usp on a live Windows system, use the –livesys option to tell it to analyze the currently running registry hives and setupAPI logs. Having administrator's access is required, since usp will take a snapshot of the appropriate hives on disk and start analyzing them. The output is text and can be very large, depending on how many USB devices were plugged into the computer over the life of the operating system. Therefore, it is recommended to redirect the output to a file as shown below, and analyze the output with a text editor.
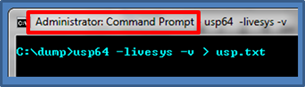
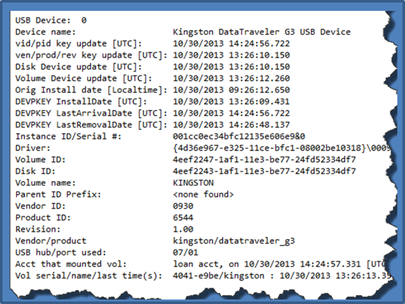
The above command redirected all output from usp to a results file named 'usp.txt'. When opening the results file in notepad, a summary of the devices are listed with: device name, various timestamps, various identifiers, volume name, account name that mounted the device, and other miscellaneous data. The truncated diagram shows the output of the first USB device, which is labeled a "Kingston DataTraveler 2.0 USB Device". The key timestamps are the original install date and the account that mounted the device, which should be the last time that user account plugged in the device. Other useful data include the Instance ID/serial number, which should be unique for that device. I say should, since some vendors do not supply a unique number, but from the empirical data, most do try to honor the USB specification.
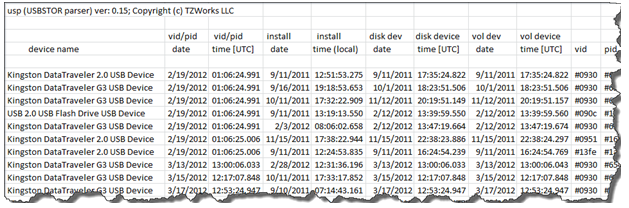
The second way one can output the data is to display each USB device on its own row with the various metadata for that devices as columns. While the option for usp is labeled as –csv, for Comma Separated Values, the default delimiter is the pipe character. The pipe was chosen as the default character, since some filenames have commas as part of the name. To use a different character for the delimited, one can append the –separator <"character(s)" to use> option to the command, where one can make the delimiter a comma instead. Since there is this issue that some filenames use commas, usp tries to substitute any commas it sees in the names to spaces. Below is an example of the output displayed using Microsoft Excel:
Example 2. Processing USB Artifacts from a 'dd' image of an NTFS disk
The preconditions for processing an image, whether it be an image from an entire disk or just one volume, are as follows: (a) the image is a bit-fo-bit copy of the drive or volume, without compression or some other proprietary format and (b) the system volume is formatted as NTFS. For the situation where the image was of a disk, one needs to supply the volume offset as well. Specifically, one needs to identify to usp what offset in bytes, from the start of the image, is the location of the system volume. The switches that are used in usp are –image <filename of image> and –offset <numeric value of start of volume>. Assuming the offset is not at zero (which implies an image of a volume vice disk), both options need to be supplied for this to work.
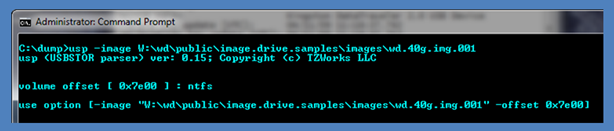
To aid the user in doing this quickly, one can use usp in a two-step procedure. For the first step, usp will accept just the first option –image <filename of image> by itself, and then will analyze the image to see if there are any NTFS volumes on it. If it finds one or more, it will list their respective offsets. An example is shown below. The image is from a 40G drive that has one volume formatted as NTFS. By supplying just the image filename, usp displays to the user the offset of the NTFS volume it found and then suggests what options to plug into the command line.
After the volume offset has been discovered, one can then proceed to the second step and supply this offset into the option –offset <numerical value of start of volume> to get usp to start scanning for the proper files it needs and outputting any USB statistics. Below is the final command based on the data provided by usp for the volume's offset. The output is redirected to a file and the file is then opened in notepad.

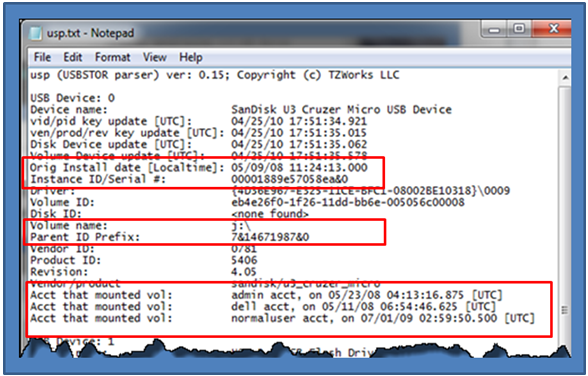
Looking at the output, one can see that there is a Parent ID Prefix present. This means that the operating system of the volume analyzed is pre-Vista, and in this case happens to be Windows XP. The first device listed is a 'SanDisk U3 Cruzer Micro USB' device, and from the data, was initially plugged in on 5/09/08. There were three user accounts that used this same device, as shown below. From the data, the last account to use the device was 'normaluser' on 07/01/09.
Example 3. Processing USB Artifacts from extracted components
This is a situation where you have acquired a number of artifacts extracted from a Windows system, but don't have an image of the drive or volume. usp can handle this, if the user explicitly identifies which artifact is a system hive, which is a user hive, etc.
An easy way to demonstrate this use-case is to make use of a tool to extract the registry hives from a computer. In this example, we use the 'ntfscopy' utility from our website (ntfscopy). This utility allows one to copy any file from an NTFS filesystem. This is especially handy for copying a file when the operating system locks down the file, disallowing one to have even read access.
Once all the desired artifacts are collected, invoke usp with the –sys <system hive> -sw <software hive> -user "<user1 hive> | <user2 hive> | … | <user# hive>" -setupapi <setupAPI log> options. Notice that one can include as many user hives as desired.
Example 4. Processing USB Artifacts from an externally mounted drive
This option is for the cases where you have an external hard drive and you want to analyze it without imaging it. In this case, one can put the hard drive under analysis in an external hard drive docking station with an interface to a write blocker and mount it as a separate volume. The syntax available allows one to access the drive in one of two ways, either as a mounted volume or as a mounted drive. The syntax for a mounted volume is: -partition <volume letter>. The syntax for a mounted drive is –drivenum <drive #> -offset <system volume offset>. The first is the easiest to use while the second forces the USB analysis to be directed to a particular volume offset. The output options are the same as in the previous use-cases.
Example 5. Pulling USB Artifacts from a Monolithic VMWare NTFS image
Occasionally it is useful to analyze a VMWare image, both from a forensics standpoint as well as from a testing standpoint. When analyzing different operating systems, and different configurations, a virtual machine is extremely useful in testing out different boundary conditions. This option is still considered experimental since it has only been tested on a handful of configurations. Furthermore, this option is limited to monolithic type VMWare images versus split images. In VMWare, the term split image means the volume is separated into multiple files, while the term monolithic virtual disk is defined to be a virtual disk where everything is kept in one file. There may be more than one VMDK file in a monolithic architecture, where each monolithic VMDK file would represent a separate snapshot. More information about the monolithic virtual disk architecture can be obtained from the VMWare website.
When working with virtual machines, the capability to handle snapshot images is important. When processing a VMWare snapshot, one needs to include the parent snapshot/image as well as any descendants.
usp can handle multiple VMDK files to accommodate a snapshot and its descendants, by separating multiple filenames with a pipe delimiter and enclosing the expression in double quotes. In this case, each filename represents a segment in the inheritance chain of VMDK files (eg. –vmdk "<VMWare NTFS virtual disk-1> | .. | <VMWare NTFS virtual disk-x>" ). To aid the user in figuring out exactly the chain of descendant images, usp can take any VMDK file (presumably the VMDK of the snapshot one wishes to analyze) and determine what the descendant chain is. Finally, usp will suggest a chain to use.
Below is an example of selecting the VMDK snapshot image file of Win7Ultx64-000002.vmdk (yellow box). Since the chain is incomplete, usp responds with what the dependencies are (shown in the red box), and then gives the user a suggested syntax to use for the command line to process this snapshot.
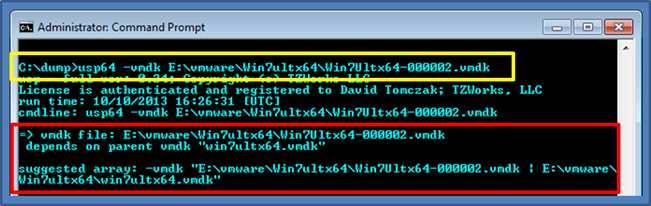
Repeating the command using the suggested chain of VMDK files, usp analyzes
the chain, verifies it is valid, and if successful, outputs the results of the
USB statistics for this snapshot of the NTFS volume.
Example 6. Pulling USB Artifacts from a Volume Shadow Snapshot
Volume Shadow Copies of the operating system drive contain the artifacts necessary to perform USB analysis from a past history standpoint. By using the option -vss <index of the volume shadow snapshot>, usp can automatically pull the required hives and log data to generate a report on USB activity.
For example to pull the USB activity from Volume Snapshot 1, the syntax would be:
usp -vss 1 -csv > out.csv
For more information
The user's guide can be viewed here
If you would like more information about usp, contact us via email.
Downloads
| Intel 32-bit Version | Intel 64-bit Version | ARM 64-bit Version | ||||
| Windows: | usp32.v.0.80.win.zip | usp64.v.0.80.win.zip | usp64a.v.0.80.win.zip | md5/sha1 | ||
| Linux: | usp32.v.0.80.lin.tar.gz | usp64.v.0.80.lin.tar.gz | usp64a.v.0.80.lin.tar.gz | md5/sha1 | ||
| Mac OS X: | Not Available | usp.v.0.80.dmg | usp.v.0.80.dmg | md5/sha1 | ||
| *32bit apps can run in a 64bit linux distribution if "ia32-libs" (and dependencies) are present. | ||||||