CSV Data eXchange (csvdx)
Introduction
csvdx is a prototype command line, support tool that converts delimited data (such as CSV data) into other formats. Currently csvdx supports conversion to: (a) HTML table data, (b) JSON format, and (c) a SQLite database. These formats are useful if desiring to: (a) displaying the data in other viewers (b) importing the original delimited data to other databases, or (c) just trying to merge similar artifacts together. Pictorially the functionality of csvdx is shown below:
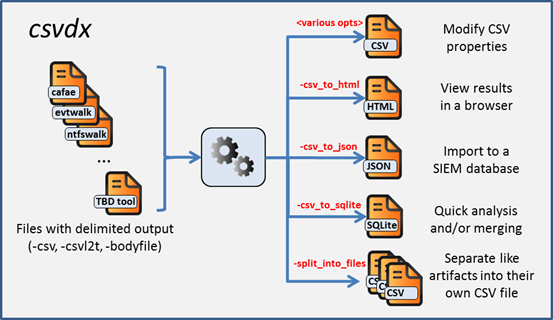
CSV stands for Comma Separated Values. However, in this document, the term CSV will also be used to refer to other delimiters as well, such as tab delimited, pipe character delimited, etc. Currently, csvdx can handle: comma, tab and pipe delimiters.
Extra Data in the Output of TZWorks Tools
The default behavior for tools built by TZWorks is to generate a banner at the top of the file before proceeding with any delimited data. This banner contains some additional information that can be useful, if retained, when converting the delimited data to another format. Information such as: (a) the command line options used to parse the original artifact, (b) the timestamp when the parsing was done, (c) the license /organization that conducted the parsing, and (d) which version of the tool was used. csvdx reads this banner data and subsequently embeds it to the converted format so it is preserved.
The other, non-standard CSV data that may be present in TZWorks tools is when processing differing artifact types and storing the results in one CSV file. In these cases, the differing artifacts may have different columns which correspond to the different fields of artifact being processed. Good examples of this are when processing registry data via cafae or processing event logs with evtwalk. In both cases, the resulting CSV file will have multiple CSV sections. To handle this, csvdx looks at the banner data and adjusts the parsing logic based on the tool (which is recorded in the banner) that was used to generate the CSV file. When using the SQLite option to store the artifact data from the CSV file, the banner data will allow csvdx to break the data out by artifact within the SQLite database.
How to use csvdx
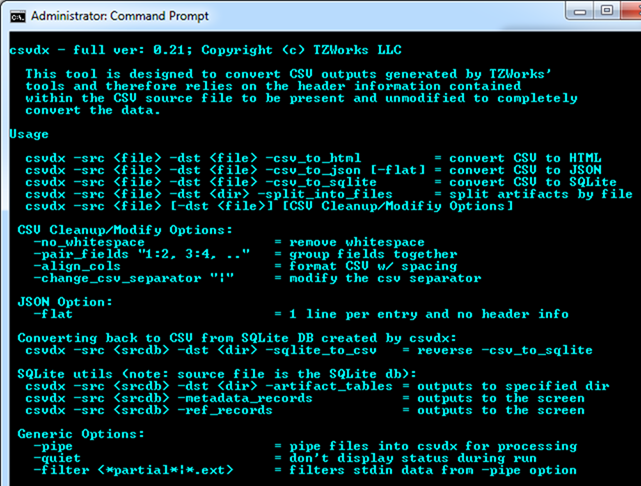
One can display the menu options by typing in the executable's name with no parameters. A screen shot of the menu is shown below:
Manipulating the CSV Data
If one is given a CSV file that has formatting properties that need to be changed, csvdx offers 4 possible options to modify the CSV file via the following switches:
-
- -no_whitespace to remove all white space (space and tabs) between the field values and CSV separators. This is the same option available in most TZWorks tools.
- -pair_fields "<field1>:<field2>" to merge two separate fields into one field. Where one may want to do this is when one field is the date field and another field is the time field, and what is desired is one field containing both the date and time. If the date field is at position 1 and the time field is at position 2, the command pair_fields "1:2" will merge the date and time (separated by a space) into one field.
- -align_cols to put spaces in between field data and the delimiters. This purpose here would be to align all the data, so that the CSV output is easy to read with notepad or some other text viewer.
- -change_csv_separator "|" to change the existing CSV delimiter to something else.
HTML Output
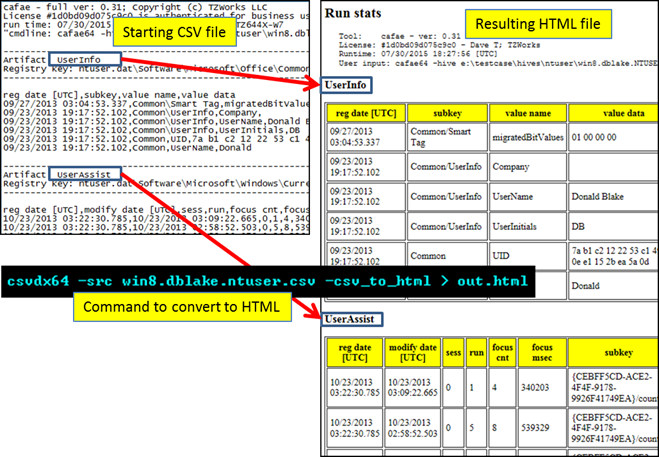
When converting from CSV data to a HTML table format, use the -csv_to_html option. Below is an example of a CSV file generated by cafae on the left, and the resulting HTML that is generated on the right. Notice the differing artifacts in the original CSV file are ported over to their respective HTML table, and the banner nformation is converted as well.
JSON Output
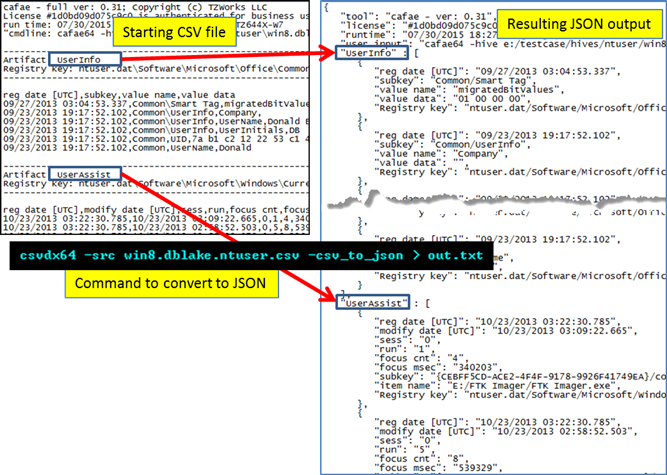
When converting from CSV data to a JSON format, use the -csv_to_json option. Below is an example using the same source data as the HTML example above.
SQLite Output
When converting from CSV data to a SQLite format, use the -csv_to_sqlite option. For each artifact that is found in the CSV data, a unique table is dynamically generated for that specific artifact. There are a few functions that should be of note: (a) csvdx has the ability to detect similar artifacts and insert into an existing artifact table if already generated, (b) on subsequent runs of csvdx, if using an existing SQLite database that was generated originally from csvdx, the artifacts will be merged into the appropriate like-artifact tables, and (c) on subsequent runs of csvdx, one can use completely different CSV tool outputs (eg. one from cafae, one from evtwalk, etc) and the artifact tables will be preserved.
After inserting all the CSV data into a SQLite database, one can extract those components that are of interest using either a custom crafted SQL select statement or by using the the prebuilt option -artifact_tables.
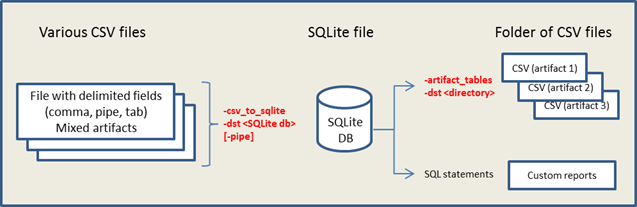
The -artifact_tables option will extract all the artifact data stored in the SQLite database back into a CSV type output. What this option does internally is: (a) reads the SQLite database specified, (b) extracts all the artifact data while merging the banner specific data pulled during the initial CSV parse with the artifact data, and (c) dumps the final output into a separate CSV files at the directory specified. Therefore, if you had 10 artifact tables to start with, you will end up with 10 unique CSV files with the data from those artifact tables.
For more information
The user's guide can be viewed here
If you would like more information about csvdx, contact us via email.
Downloads
| Intel 32-bit Version | Intel 64-bit Version | ARM 64-bit Version | ||||
| Windows: | csvdx32.v.0.43.win.zip | csvdx64.v.0.43.win.zip | csvdx64a.v.0.43.win.zip | md5/sha1 | ||
| Linux: | csvdx32.v.0.43.lin.tar.gz | csvdx64.v.0.43.lin.tar.gz | csvdx64a.v.0.43.lin.tar.gz | md5/sha1 | ||
| Mac OS X: | Not Available | csvdx.v.0.43.dmg | csvdx.v.0.43.dmg | md5/sha1 | ||
| *32bit apps can run in a 64bit linux distribution if "ia32-libs" (and dependencies) are present. | ||||||