Windows Journal Parser (jp)
Introduction
jp is a command line tool that targets NTFS change log journals. The change journal is a component of NTFS that will, when enabled, record changes made to files.
The change journal will record amongst other things: (a) time of the change, (b) affected file/directory, (c) change type (eg. delete, rename, size extend, etc), and therefore makes a useful tool when looking at a computer forensically. Each entry is of variable size and its internal structure is documented in the MSDN.
Microsoft provides tools to look/affect the change journal as well as a published API to programmatically read/write from/to the change log. jp however, doesn't make use of this Windows API, but does the parsing by traversing the raw structures. This allows jp to be compiled for use on other operating systems to parse the change journal as a component in a forensic toolkit.
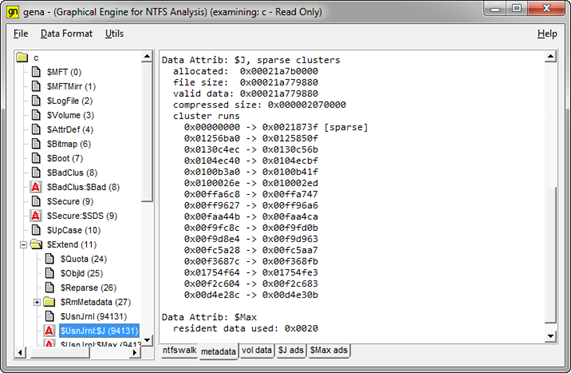
To find the change journal, one needs to look into the root directory of the volume under analysis. Buried within one fo the hidden system files, is an alternate data stream containing the change log journal. Specifically, the journal data is located at the [root]\$Extend\$UsnJrnl:$J, where the $J is an alternate data stream. Looking at this location with an NTFS viewer (shown below), one can easily drill down to the proper location and analyze the contents. When examining the cluster run for the $J data stream, one will see the beginning clusters are sparse, meaning they are not backed by physical disk clusters, and the latter (unsparsed) clusters have data. For the example below, 2,197,312 (or 0x218740) clusters are sparse and only 8304 (or 0x2070) clusters have data in them.
The data within the journal is a series of packed entries. The structure for each entry is defined in the Microsoft Software Development Kit (SDK).
Overall Options
For live extraction and analysis, the jp tool requires one to run with administrator privileges; without doing so will restrict one to only looking at extracted change log journals. One can display the menu options by typing in the executable name with no parameters. A screenshot of the menu is shown below:
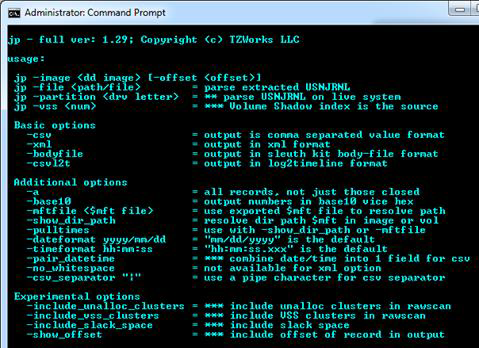
From the menu above, there are three primary data source options: (a) input from an extracted journal file, (b) a 'dd' image of a volume or disk, and (c) a mounted partition of a live Windows machine. jp can handle each equally well. The latter two, however, actually can yield more data, if desiring to cross-reference the MACB timestamp data from INDX slack space when looking at deleted items.
All the data source options allow one to reconstruct the parent path of the journal entry, using the appropriate switches. This is useful for identifying where the target file or directory was from. As a separate option, jp allows one to explicitly point to a $MFT exported file to use for path reconstruction. If jp points to a volume or an image, then the tool will use the associated embedded $MFT file to extract the necessary metadata, however if an external $MFT is provided, then the external $MFT file will take precedence.
The $MFT file is also useful for extracting standard information MACB times that are related to the journal entry. This can be done via the -pulltimes option. Normally, this option just pulls the MACB times from the appropriate $MFT entry. However, if there is no $MFT entry, jp will perform additional analysis and start looking at the slack space of the parent directory's INDX records to see if it can find a match. If it finds a matching entry, it will extract the MACB timestamps from the slack and report it in the output. This additional parsing of INDX slack space comes from the the wisp engine, and has the restriction that it needs access to the entire volume when doing its analysis.
CSV Output
There are four output format options available, ranging from: (a) the default CSV output, (b) XML format, (c) Log2Timeline format and (d) Body-file format defined by the Sleuth Kit.
For an example of what fields are displayed, see the snapshot below.
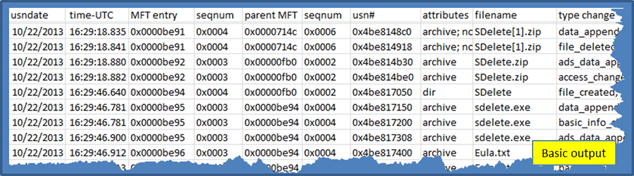
When using path reconstruction and adding times to the output, the data can make a long record. For this example, we display the same entries as the above example, but broke it up into two screenshots. The first image is the same as the one above, and the second image (below) is the extra data that shows the path reconstruction and timestamps, if they were available. To make the example more interesting, we targeted deleted journal records to show how jp parses and displays information about the data coming from slack INDX records. The wisp recovered entry is highlighted in the figure.
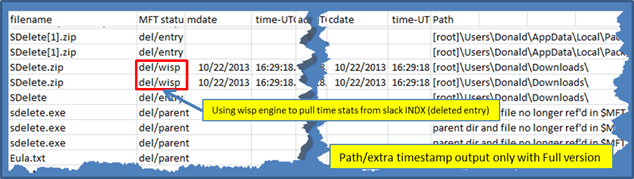
During any path reconstruction, where there are deleted entries and old inode numbers have been recycled into new directories and/or files, there exists the issue of handling false positives. Therefore, starting with version 1.09, jp looks at both the inode and sequence number to determine if there is a match (for both the parent and target entry). To try to make it clearer to the analyst, the following data is annotated using the nomenclature in the table below to each entry.

Time resolution and Date Format
Another feature is the ability to change the date and/or time format to conform to whatever standard that is desired, with a few restrictions. The time format allows one to show as much (or as little) precision that the Windows native FILETIME allows, which is documented to have a resolution of 100 nanoseconds.
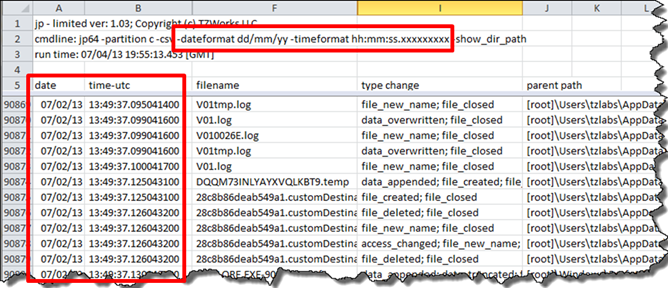
Since the FILETIME format allows for 100 nanosecond resolution, one can display this resolution if desired. The -timeformat field allows one to throttle this by just adding more x's to the end of the template argument (hh:mm:ss.xxx). This becomes more important when you want to determine the order of events when they are closely aligned in time, as are the change journal entries.
Also shown in the example, is the use of the -dateformat option to modify from the default mm/dd/yyyy format to a dd/mm/yy format.
For more information
The user's guide can be viewed here
If you would like more information about jp, contact us via email.
Downloads
| Intel 32-bit Version | Intel 64-bit Version | ARM 64-bit Version | ||||
| Windows: | jp32.v.1.50.win.zip | jp64.v.1.50.win.zip | jp64a.v.1.50.win.zip | md5/sha1 | ||
| Linux: | jp32.v.1.50.lin.tar.gz | jp64.v.1.50.lin.tar.gz | jp64a.v.1.50.lin.tar.gz | md5/sha1 | ||
| Mac OS X: | Not Available | jp.v.1.50.dmg | jp.v.1.50.dmg | md5/sha1 | ||
| *32bit apps can run in a 64bit linux distribution if "ia32-libs" (and dependencies) are present. | ||||||