Graphical Engine for NTFS Analysis (gena)
Introduction
One item we hear repeatedly is a request to provide a GUI (Graphical User Interface) front end to some of the TZWorks command line tools. While we internally prefer command line tools for automated processing, we do have a handful of GUI based tools that we develop for internal use only, primarily for reversing and analyzing new artifacts. So we decided to take one of our internal tools, take out some of the more arcane options, and merge the backend processing with ntfswalk and some other tools to come up with gena.
The name gena is short for Graphical Engine for NTFS Analysis. Along the way, we made some significant additions to ntfswalk, as well, to allow gena to be used as a flexible tool for data extraction. (note: gena only works with ntfswalk version 0.45 or above). We also incorporated some capabilities from ntfscopy, ntfsdir, and wisp into gena. So while this subject is about gena, there are references to some of these other tools throughout.
Similar to the other TZWorks tools that were mentioned, gena is designed to work with live (mounted) NTFS volumes. There is also functionality for traversing either NTFS images (a) created with the dd utility or (b) from a monolithic volume consisting of VMWare VMDK files. Whether gena is being used for live incident response collection or to process an image in an off-line manner, there are options to filter on: (a) file extensions, (b) a timestamp range, (c) various binary signatures, (d) partial filenames and (e) directory contents. For targeted files found, one can list the summary metadata, extract the header bytes of the file data, or extract the entire file contents into a designated directory. Since the GUI front end and backend parsing engine are both Windows API agnostic, there are compiled versions for Windows, Linux and Mac OS X.
Layout of gena
The gena GUI is divided into two main window panes. The first pane is on the left, and is a quasi-Windows Explorer view of the volume under analysis. The right pane is governed by a series of tabs that reflect differing functionality. The number of tabs is dependent on the MFT record (or inode) that is selected on the left tree-view pane. This is the area where one can invoke the ntfswalk tool or peer into the details of an MFT record. The first and default tab is for the ntfswalk dialog. It exposes various options unique to ntfswalk.
When one loads a volume for analysis, a series of additional tabs automatically become visible. This includes: a tab for MFT record metadata (timestamp, cluster runs, etc.), a tab for the hexadecimal dump of the file record under analysis, and a separate tab for each NTFS attribute containing data. The term data defined here, can include: (a) the unnamed data stream, (b) any alternate named data streams, (c) the directory's INDX data, (d) a Logged Stream data, and (e) various others. To keep things simple, each unique data set is selectable with a separate data tab.
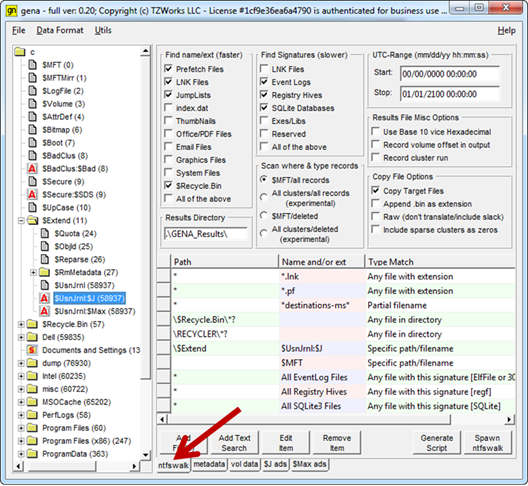
Below is a screen shot of gena in preparation to copy files from the 'c' partition on a live system. The right pane is the ntfswalk tab of shows what items are desired to extract from the volume. The checkboxes define what category of files to extract and the listbox enumerates the specific files (or types of files) to extract. One is allowed to fine tune the selection (or add custom filters) via the buttons on the bottom of the list box. To execute the collection on can either press the 'Spawn ntfswalk' button or 'Generate Script button. The former will spawn ntfswalk as a separate process and pass all the options specified in gena to the new process, and the collection will immediately start. One can spawn as many parallel instances of ntfswalk as the host machine resources allow, giving one the ability to process a number of separate images in parallel.
gena can analyze four types of source data. This includes: (a) NTFS drive/volume stored as a 'dd' type image, (b) NTFS mounted drive/volume, (c) an exported $MFT file, or (d) a VMWare volume. To analyze an image or mounted volume, one uses the 'File' menu to selected the desired data source.
Format Options
There are a few data format options, grouped by the following categories: (a) Final output, (b) Date Format, and (c) Time Resolution.
The first category, final output, tells gena how to format the results file ntfswalk produces. This can either be: (a) default output, (b) CSV format, (c) Log2Timeline format, (d) BodyFile format or (e) a Hashfile. The last one is new to the ntfswalk capabilities, and was added based on user input.
The second category is date format. Date format can be selected based on desired convention. Three common format options are offered: mm/dd/yyyy, dd/mm/yyyy or yyyy/mm/dd. The default is set to the USA convention of: mm/dd/yyyy.
The third category is time format and it has three resolution options: (a) seconds, (b) milliseconds and (c) microseconds. The default is set to milliseconds.
Looking at Slack Directory Entries
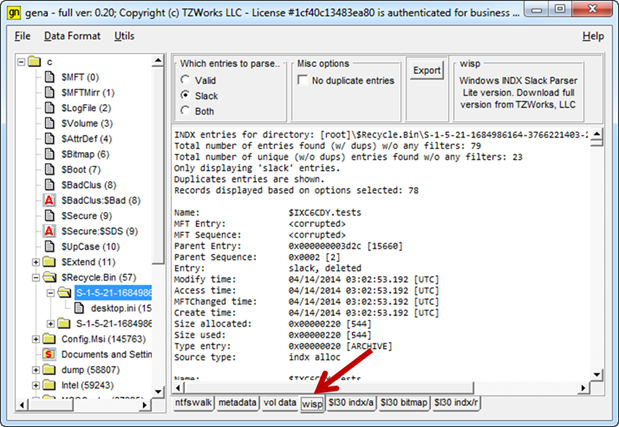
When selecting any directory from the tree view, a wisp (Windows INDX Slack Parser) tab is displayed. Since gena can parse the INDX attribute to find the children to a directory, we incorporated a lite version of the TZWorks wisp engine. This will allow gena not only to parse normal children but also slack entries (or children that have been deleted). This is very useful in identifying deleted files after they have been wiped from the NTFS volume, since the file artifact could still be in the parent directory's INDX attribute.
Each entry will have a name, file size, and a set of timestamps. For additional verification, we added the ability for each entry to show the source data (or hex dump of the data that was parsed), complete with actual offset of where the data resides in the INDX cluster run.
In the screen shot below, the $Recycle.Bin is examined, specifically the subdirectory named with the users' security identifier (SID). In this directory, only one file is shown (the desktop.ini file), which means the user cleaned out the trash. When going to the wisp tab, however, and selecting the 'Slack' radio button, on can see from the summary text that wisp was able to identify just under 20 thousand entries.
Looking at the Various Raw Data in an MFT entry
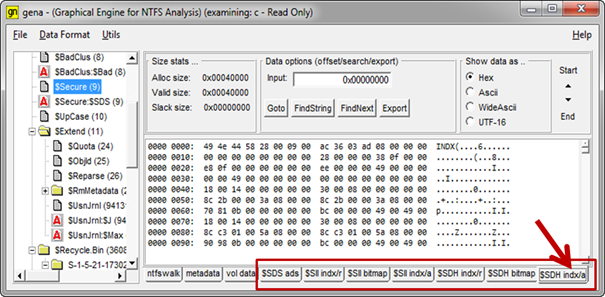
gena is very useful for displaying file data. Not only does it show the normal data (unnamed data stream) and the alternate (named) data stream, but it also shows the Bitmap data, Logged Stream data, and various types of INDX data. A good example is looking at the $Secure MFT entry (inode #9). It has a number of attributes that contain data. Without going into too much detail, it contains: (a) an $SDS alternate data stream, (b) $SII index root and allocation attributes, (c) $SII bitmap attribute, (d) $SDH index root and allocation attributes, and (d) an $SDH bitmap attribute.
While some of the attributes might only have a little bit of data or the data may reside as resident data within the file record itself, gena will display a separate tab for each data category.
Within each of these data tabs, are options to go to a specific offset, find a string or pattern or export the data to a separate file to analyze with another forensics tool. In some cases it may be useful to represent the data as ASCII or Unicode instead of hexadecimal, so those options are there as well. See below:
Generating Hash Sets on Targeted File Types
There are a number of excellent tools present on the Internet that perform hashing and creating hash sets. While ntfswalk was not originally designed to generate hash sets, it does have the ability to hash any desired target file. The main difference between ntfswalk's approach to that of a normal hash tool, is ntfswalk accesses the file contents at the cluster level whereas many other hashing tools do not. This becomes more important when considering our age of malware, and whether the actual file contents we are viewing have been masked by malicious software.
In using gena as the front end, one can, for example select all the files with a signature used in executables, device drivers or libraries, and select the menu option 'Hashfile' under the 'Final output'.
After spawning ntfswalk, the results file will contain a list of executable files with their computed hashes. Both the MD5 and SHA1 hashes are computed per file processed.
For more information
The user's guide can be viewed here
If you would like more information about gena, contact us via email.
Downloads
| Intel 32-bit Version | Intel 64-bit Version | ARM 64-bit Version | ||||
| Windows: | gena32.v.0.61.win.zip | gena64.v.0.61.win.zip | gena64a.v.0.61.win.zip | md5/sha1 | ||
| Linux: | gena32.v.0.61.lin.tar.gz | gena64.v.0.61.lin.tar.gz | gena64a.v.0.61.lin.tar.gz | md5/sha1 | ||
| Mac OS X: | Not Available | gena.v.0.61.dmg | gena.v.0.61.dmg | md5/sha1 | ||
| *32bit apps can run in a 64bit linux distribution if "ia32-libs" (and dependencies) are present. | ||||||